Prometheus 是一款时序(time series)数据库, 并支持自动化收集各种系统的输出指标。
prometheus的4种监控指标
- Counters 计数器
- Gauges 仪表/测量
- Histograms 直方图
- Summaries 汇总
Promethues 获取指标
本项目通过 SpringBoot Actuator 输出Java 项目指标,具体配置如下:
# management.endpoints.web.exposure.include=*
management:
security:
enabled: false
# Prometheus
metrics:
tags:
application: ${spring.application.name}
endpoints:
web:
base-path: /actuator # 配置 Endpoint 的基础路径
exposure:
# include: "*"
include: ["health", "info", "jvmMetrics", "metrics", "env", "prometheus-endpoint"]
endpoint:
auditevents: # 1、显示当前引用程序的审计事件信息,默认开启
enabled: true
cache:
time-to-live: 10s # 配置端点缓存响应的时间
beans: # 2、显示一个应用中所有 Spring Beans 的完整列表,默认开启
enabled: true
conditions: # 3、显示配置类和自动配置类的状态及它们被应用和未被应用的原因,默认开启
enabled: true
configprops: # 4、显示一个所有@ConfigurationProperties的集合列表,默认开启
enabled: true
env: # 5、显示来自Spring的 ConfigurableEnvironment的属性,默认开启
enabled: true
health: # 7、显示健康信息,默认开启
enabled: true
show-details: always
info: # 8、显示任意的应用信息,默认开启
enabled: true
metrics: # 10、展示当前应用的metrics信息,默认开启
enabled: true
prometheus:
enabled: true
shutdown:
enabled: false项目启动后,可通过浏览器:http://localhost:1966/yoloapi/actuator/prometheus-endpoint 查看指标数据(如:jvm,GC 指标信息)。
Prometheus 通过 enppoint 获取项目指标:
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: "prometheus"
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ["localhost:9090"]
- job_name: 'Yolo-ApiServer Exporter'
metrics_path: /yoloapi/actuator/prometheus-endpoint
static_configs:
- targets: ['192.168.31.10:1966']Grafana 看板制作
Grafana 搭建后,通过 admin 登录,创建看板。
Grafana 看板变量
admin 登录 grafana 后,再看板右上角的设置按钮,进入到看板设置。Variables 可以创建变量,Grafana 变量可在看板上方显示,方便多个实例选择,并再 promQL 作为变量使用。
通过创建 Name、Label、Description、Query 等配置,实现变量。
label_values(up{job="Yolo-ApiServer Exporter"}, instance)- label_values 是作为输出查询结果,instance 是输出查询结果的变量;
- up{job="Yolo-ApiServer Exporter"} 是查询语句,可以采用任意 Prometheus 上能执行的 promQL 语句。
如上,创建了一个 Name 名为 javaapp 的变量,变量值是 up{job="Yolo-ApiServer Exporter"} 查询结果。
静态变量值
创建变量,采用 Label And Value, 并在 Values 输入逗号分割的值,如:30s,1m,2m,3m,5m,10m,30m
那么在看板上,会展示每个逗号作为选择的下拉框。
Grafana 看板图表
创建简单的图表,再 JVM Prometheus,一般都会输出 JVM 参数信息,如:jvm_memory_bytes_used, 显示 JVM 内存使用情况。
jvm_memory_bytes_used{instance="$javaapp"}通过 Run Queries 可实时看到可视化结果。
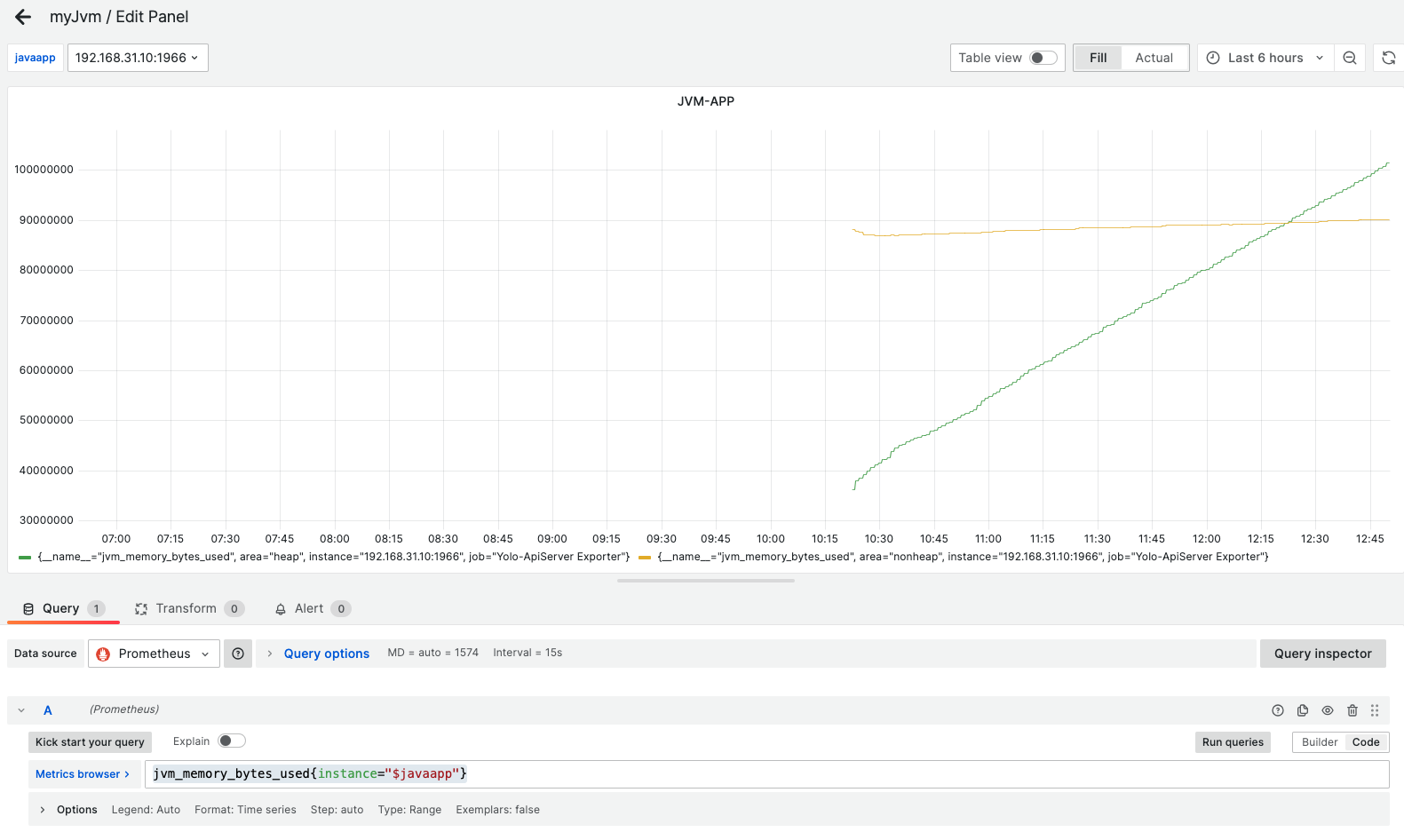
可看到 Grafana 上方,显示了 javaapp 的变量,并提供了下拉框,方便选择不同的实例。
Grafana 看板浏览模式
Grafana 看板支持用户独立访问,通过设置 kiosk 模式,可以方便用户访问。
https://localhost:3000/grafana/d/YmYZNQ0Hz/myjvm?orgId=1&refresh=1m&kiosk=1&theme=light- kiosk:1 表示开启 kiosk 模式,去除菜单栏;kiosk=full/1
- theme: 默认采用亮色主题;
- refresh=1m:1分钟数据自动刷新一次;
Prometheus PromQL
简单查询
- up/up{} 可输出当前在线的实例;
- up{name="value"} 进行筛选;
- 在Prometheus 指标上看到的任意指标,都可以作为 promQL 查询语句。
- instance, job 是两个特殊的变量,instance 是一个监控进程实例,job 是一个监控分组。如:hosts 是 job,多个 host 是 instance;
时间聚合
- rate
rate函数用于计算一个时间序列在给定时间范围内的平均速率。它对每个数据点进行线性插值来计算速率,因此对于平滑和稳定的数据来说,rate是一个不错的选择。语法如下:
rate(metric_name[time_range])metric_name: 指标名称。 time_range: 时间范围,例如5m表示过去5分钟。示例:
rate(http_requests_total[5m])这个查询返回的是http_requests_total指标在过去5分钟内的平均请求速率。
- irate
irate函数用于计算时间序列的瞬时速率。它仅使用时间范围内的最后两个数据点来计算速率,因此对于检测突发变化或短期波动非常有用。语法如下:
irate(metric_name[time_range])metric_name: 指标名称。 time_range: 时间范围,例如5m表示过去5分钟。示例:
irate(http_requests_total[5m])这个查询返回的是http_requests_total指标在过去5分钟内的瞬时请求速率。
选择rate还是irate:
- 如果你需要一个平滑的平均速率,可以选择rate。
- 如果你需要捕捉短期的突发变化或尖峰,可以选择irate。
- avg
聚合函数,求单位时间内均值。在 Prometheus 中,avg 函数用于计算一段时间内某个度量指标(metric)的平均值。这对于监控和告警系统来说非常重要,因为它可以帮助你理解数据在一段时间内的整体趋势,而不仅仅是瞬时值。
avg_over_time(cpu_usage_seconds_total[10m])然后选择一个合适的时间范围和刷新间隔,Grafana 会自动绘制出该时间段内 CPU 使用率的平均值图表。
与其他聚合函数结合使用 avg 函数可以与其他聚合函数结合使用,以获取更复杂的分析结果。例如,你可以先对多个实例进行分组,然后再计算每个组的平均值。
avg by (instance)(rate(cpu_usage_seconds_total[5m]))这个查询会先计算每个实例在过去 5 分钟内的 CPU 使用率变化率(通过 rate 函数),然后按实例分组并计算每组的平均值。
注意事项
确保你的度量指标名称和时间范围是正确的。错误的度量指标名称或不合理的时间范围可能会导致查询失败或结果不准确。 avg 函数仅适用于数值类型的度量指标。对于非数值类型(如字符串或布尔值),Prometheus 无法计算平均值。 当处理高基数(high cardinality)度量指标时(即具有大量不同标签组合的度量指标),请注意性能问题。大量的数据点和复杂的查询可能会增加 Prometheus 服务器的负载。
用聚合函数avg,求一个instance分组内,每个机器cpu空闲平均值
avg(irate(node_cpu_seconds_total{host="node1",env=~"test",mode="idle"}[5m]) by (instance)