前置环绕配置
前置环绕
类型:RDBMS(mysql/oracle)、HTTP
支持 ${name} 模式的宏替换:
xml
<round type="mysql"
sql="insert into cpic_task_history(id, task_type, catalog_model, start_time, retry_count, final_status, created_at)
values(${uuid}, ${task.type}, ${catalog.model}, ${starttime}, 0, ${status}, now())"
url="${jdbc.url}"
driver="${jdbc.driverclass}"
user="${jdbc.user}"
password="${jdbc.password}" />参数支持:
- 支持 property 中定义的变量;
- 支持 jvm system property 变量;
- 支持 Flow 运行期产生的变量;
Flow 运行期变量:
- uuid 每个任务生成唯一的ID STRING
- starttime 任务运行开始时间 Timestamp
- endtime 任务运行结束时间 Timestamp
- inputBytes 任务读入的数据量字节大小计数 Long
- inputRecords 任务读入的数据量 Long
- outputBytes 任务输出的数据量总字节大小计数 Long
- outputRecords 任务输出的数据量 Long
- jobCount Spark 分解的任务量 Long
- taskCount Spark 分解的 Task 任务量 Long
- status 任务的当前状态:RUNNING STRING
- error 任务运行失败时的异常 STRING
Status 可选的值为:
- RUNNING;
- SUCCEEDED;
- FAILED;
使用 Round 更新:
xml
<round type="mysql"
sql="update cpic_task_history set
end_time = ${endtime}, final_status = ${status}, error_text = ${error} where id = ${uuid}"
url="${jdbc.url}"
driver="${jdbc.driverclass}"
user="${jdbc.user}"
password="${jdbc.password}" />Prepare round 和 after round 配合使用可用于记录 SparkSQL Flow 任务的运行日志:
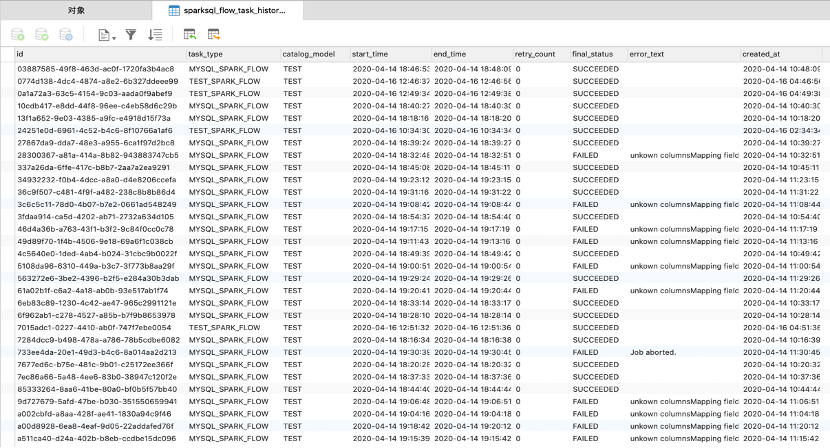
和 After Round 使用方法相同,见:【After Round】
SQL环绕
SQL 指在 Flow 运行前可通过 Spark SQLContext 执行一段 SQL。如:可以是 use 切换库,可以是创建表,可以是删除表等;
xml
<sql>
<![CDATA[
use default
]]>
</sql>建议 使用 CDATA 包装起来,防止 SQL 有>,<等需要转义的字符无法正常表达。
多条 SQL 默认支持分号分割“;”,这些 SQL 可以是一些 hive,或者 sparksql 的设置。如写入 Hive 多分区的前置设置:
sql
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
set hive.exec.max.dynamic.partitions.pernode=1000;