提示
本文简单介绍 apache-iotdb 的安装和简单使用,重点在于操作实践,便于理解 iotdb 的数据类型,数据结构,查询方法。
调研背景:
公司大量的传感器(车辆网)数据都是存储到 ES 中,架构比较老,ES 存储数据量大,消耗内存过高,又不能上大数据系统。只能再小范围选择。老早就听过 IOTDB 未能上手,正好可学习一下。于是弄了几千万数据,进行快速实践。
IOTDB安装
安装前准备
- 已有JDK1.8级以上运行环境,且 JAVA_HOME 环境变量已经配置好。
- 系统设置最大文件打开数 和 最大连接 都为 65535
#最大文件打开数为 65535
ulimit -n 65535
#最大连接 65535
sysctl -w net.core.somaxconn=65535- 防火墙操作
#关闭防火墙
systemctl stop firewalld.service
systemctl disable firewalld.service配置IOTDB
iotdb/conf/ 目录下,找到 iotdb-datanode.properties 文件,并编辑对应的 dn_rpc_address,改为当前服务器的IP,开启远程连接支持。
相同目录下,找到 confignode-env.sh 文件,对应 Windows 版本是 confignode-env.bat 文件,修改 MAX_HEAP_SIZE 值。
此是设置最大堆内存大小,在 Linux 或 MacOS 系统下默认为机器内存的四分之一。在 Windows 系统下,32位系统的默认值是512M,64位系统默认值是2G。
如果不需要改,使用默认值也可以。
启动IOTDB
在安装目录的 sbin 下,调整对应所有启动文件的权限,再进行启动。
cd /usr/local/iotdb/sbin
chmod a+x start-standalone.sh
chmod a+x start-confignode.sh
chmod a+x start-datanode.sh
chmod a+x start-all.sh
./start-standalone.sh采用客户端连接
sbin/start-cli.sh -h 127.0.0.1 -p 6667 -u root -pw root基本使用
管理DML
IOTDB 的数据库模型依次为:DATABASE(库)、DEIVCE(设备)、TIMESERIES(测点)。
列举库表
show databases;
show devices;
+--------------------+---------+--------+
| Device|IsAligned|Template|
+--------------------+---------+--------+
|root.ln.hyd.gate1004| false| null|
| root.in.hyd.v2025| true| null|
+--------------------+---------+--------+
Total line number = 2
It costs 0.025s
show TIMESERIES;
+--------------------------------+-----+--------+--------+--------+-----------+----+----------+--------+------------------+--------+
| Timeseries|Alias|Database|DataType|Encoding|Compression|Tags|Attributes|Deadband|DeadbandParameters|ViewType|
+--------------------------------+-----+--------+--------+--------+-----------+----+----------+--------+------------------+--------+
|root.ln.hyd.gate1004.open_height| null| root.ln| FLOAT| RLE| LZ4|null| null| null| null| BASE|
+--------------------------------+-----+--------+--------+--------+-----------+----+----------+--------+------------------+--------+
Total line number = 1
It costs 0.042s
-- 所有时间序列数量
COUNT timeseries创建库/集合
CREATE DATABASE root.ln;
-- 创建数据对齐的测点(如一张表下的多个字段)
create aligned timeseries root.in.hyd.v2025(s1 INT32, s2 DOUBLE)
CREATE aligned TIMESERIES root.in.hyd.v2025(device_id TEXT encoding=PLAIN compressor=SNAPPY, device_type TEXT encoding=PLAIN compressor=SNAPPY)
-- 创建独立的测点
create timeseries root.ln.hyd.gate1004.open_height with datatype=FLOAT,encoding=RLE;
-- 查询某库下的 timeseries
show timeseries root.iotdb.s1.power1
-- 查看某个路径的子节点
SHOW child paths root.ln
IoTDB> SHOW child paths root.ln
+-----------+---------+
| ChildPaths|NodeTypes|
+-----------+---------+
|root.ln.hyd| INTERNAL|
+-----------+---------+
Total line number = 1
It costs 0.081s
IoTDB> SHOW child paths root.ln.hyd
+--------------------+---------+
| ChildPaths|NodeTypes|
+--------------------+---------+
|root.ln.hyd.gate1004| DEVICE|
+--------------------+---------+
Total line number = 1
It costs 0.018s
IoTDB> SHOW child paths root.ln.hyd.gate1004
+--------------------------------+----------+
| ChildPaths| NodeTypes|
+--------------------------------+----------+
|root.ln.hyd.gate1004.open_height|TIMESERIES|
+--------------------------------+----------+
Total line number = 1
It costs 0.018siotdb的库和集合
IOTDB 中有库的概念,类似于关系型数据库中的数据库,但没有表的概念。而是通过 timeseries 来表示数据集(和 mongodb 这类也不像)。timeseries 是由一个时间戳和一组数据点组成的,每个数据点都有一个时间戳和一个值(有点类似 HBase 的数据结构)。整个数据模型的结构是一个树形结构。每个树末尾节点代表一个采集点(表),采集点上可以有多个采集指标和一个时间戳。
再 IOTDB 中,库和采集点中间的子节点可以有多个,也可以没有。这个看管理的需求。
因此,再 IOTDB 中,无法做到一次性查询多个 id 的数据,比如:select metrics1,metrics2 from table where id in(a, b, c)。经过验证,可以支持 from 多个监测点,如:select device_id, device_type from root.in.hyd.v2024, root.in.hyd.v2025 ALIGN BY DEVICE;, 如果不加 ALIGN BY DEVICE 返回值是个宽表,分别包含 v2024 和 v2025 的列,还需要自行处理宽表转高表。
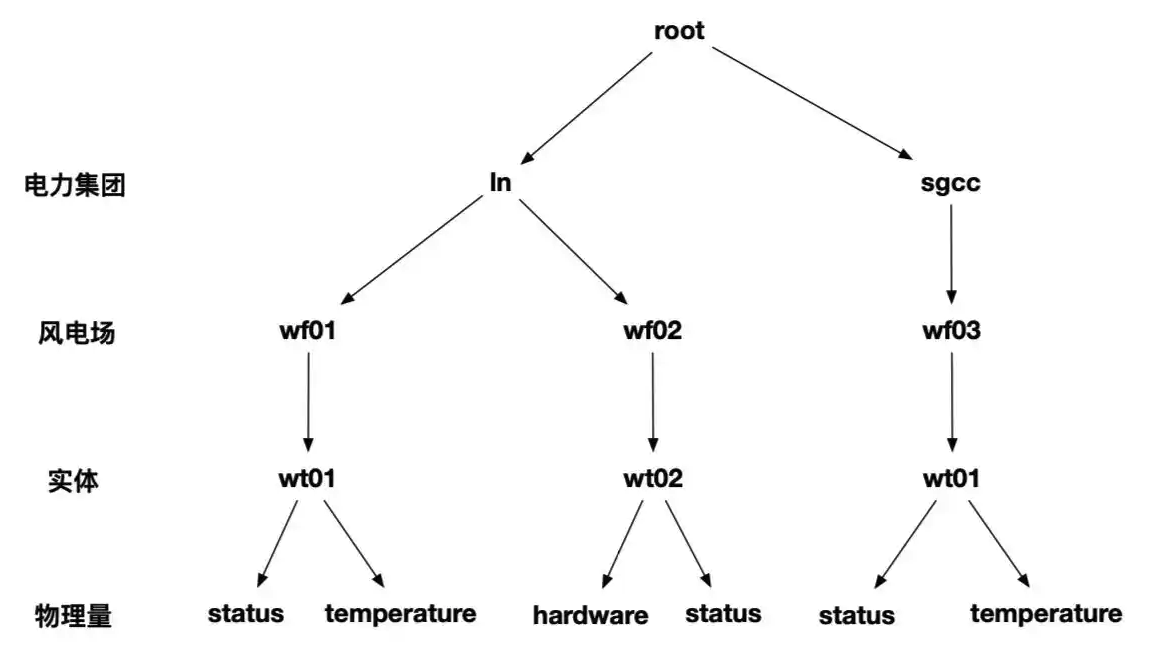
IOTDB 的 数据模型如下图。ln 和 sgcc 是库,wt01, wt02 才是 device(设备), status 和 temperature 是 metrics。经过上面的 SHOW child paths 的输出,IOTDB 的模型层级称谓:
- DB
- INTERNAL
- DEVICE
- TIMESERIES
数据类型
- BOOLEAN (布尔值)
- INT32 (整数)
- INT64 (长整数)
- FLOAT (单精度浮点数)
- DOUBLE (双精度浮点数)
- TEXT (字符串)
数据类型与其支持的编码之间的对应关系 encoding:
- RLE
- PLAIN
压缩方法
- UNCOMPRESSED
- SNAPPY[推荐的]
- LZ4
- GZIP
- ZSTD
- LZMA2
编码类型
为了提高数据的存储效率,需要在数据写入的过程中对数据进行编码,从而减少磁盘空间的使用量。在写数据以及读数据的过程中都能够减少 I/O 操作的数据量从而提高性能。IoTDB 支持多种针对不同类型的数据的编码方法:
- PLAIN 编码(PLAIN)
PLAIN 编码,默认的编码方式,即不编码,支持多种数据类型,压缩和解压缩的时间效率较高,但空间存储效率较低。
- 二阶差分编码(TS_2DIFF)
二阶差分编码,比较适合编码单调递增或者递减的序列数据,不适合编码波动较大的数据。
- 游程编码(RLE)
游程编码,比较适合存储某些数值连续出现的序列,不适合编码大部分情况下前后值不一样的序列数据。
游程编码也可用于对浮点数进行编码,但在创建时间序列的时候需指定保留小数位数(MAX_POINT_NUMBER,具体指定方式参见本文 SQL 参考文档)。比较适合存储某些浮点数值连续出现的序列数据,不适合存储对小数点后精度要求较高以及前后波动较大的序列数据。
游程编码(RLE)和二阶差分编码(TS_2DIFF)对 float 和 double 的编码是有精度限制的,默认保留 2 位小数。推荐使用 GORILLA。
- GORILLA 编码(GORILLA)
GORILLA 编码是一种无损编码,它比较适合编码前后值比较接近的数值序列,不适合编码前后波动较大的数据。
当前系统中存在两个版本的 GORILLA 编码实现,推荐使用GORILLA,不推荐使用GORILLA_V1(已过时)。
使用限制:使用 Gorilla 编码 INT32 数据时,需要保证序列中不存在值为Integer.MIN_VALUE的数据点;使用 Gorilla 编码 INT64 数据时,需要保证序列中不存在值为Long.MIN_VALUE的数据点。
- 字典编码 (DICTIONARY)
字典编码是一种无损编码。它适合编码基数小的数据(即数据去重后唯一值数量小, 如:男/女)。不推荐用于基数大的数据。
数据类型与编码的对应关系
五种编码适用于不同的数据类型,若对应关系错误,则无法正确创建时间序列。数据类型与支持其编码的编码方式对应关系总结如下表所示。
| 数据类型 | 推荐编码(默认) | 支持的编码 |
|---|---|---|
| BOOLEAN | RLE | PLAIN, RLE |
| INT32 | TS_2DIFF | PLAIN, RLE, TS_2DIFF, GORILLA, ZIGZAG, CHIMP, SPRINTZ, RLBE |
| INT64 | TS_2DIFF | PLAIN, RLE, TS_2DIFF, GORILLA, ZIGZAG, CHIMP, SPRINTZ, RLBE |
| FLOAT | GORILLA | PLAIN, RLE, TS_2DIFF, GORILLA, CHIMP, SPRINTZ, RLBE |
| DOUBLE | GORILLA | PLAIN, RLE, TS_2DIFF, GORILLA, CHIMP, SPRINTZ, RLBE |
| TEXT | PLAIN | PLAIN, DICTIONARY |
插入数据
insert into root.ln.hyd.gate1004(open_height) values(6.0)
insert into root.BHSFC.Q1.W003(timestamp,speed) values(1657472400000,2)查询和检索
select gate1004.open_height from root.ln.hyd limit 10;
+-----------------------------+--------------------------------+
| Time|root.ln.hyd.gate1004.open_height|
+-----------------------------+--------------------------------+
|2024-07-21T16:33:12.000+08:00| 0.0|
|2024-07-21T16:33:13.000+08:00| 0.0|
|2024-07-21T16:33:14.000+08:00| 0.0|
|2024-07-21T16:33:15.000+08:00| 0.0|
|2024-07-21T16:33:16.000+08:00| 0.0|
|2024-07-21T16:33:17.000+08:00| 0.0|
|2024-07-21T16:33:18.000+08:00| 1.0|
|2024-07-21T16:33:19.000+08:00| 0.0|
|2024-07-21T16:33:20.000+08:00| 0.0|
|2024-07-21T16:33:21.000+08:00| 0.0|
+-----------------------------+--------------------------------+
Total line number = 10
It costs 0.020s
select count(gate1004.open_height) from root.ln.hyd;
+---------------------------------------+
|count(root.ln.hyd.gate1004.open_height)|
+---------------------------------------+
| 320|
+---------------------------------------+
Total line number = 1
It costs 0.019s
-- 其他查询变化
select open_height from root.ln.hyd.gate1004 limit 10;
-- 查询最大最小时间, 不需要 group 聚合,本身就是按照设备分组的
SELECT MIN_TIME(status), MAX_TIME(status) FROM root.ln.wf01.wt01
-- 筛选最后一条记录
SELECT LAST temperature from root.ln.wf01.wt01
-- 查询多个时间序列
select last * from root.BHSFC.**
select field from root.**.W003;
-- 查询多个设备序列
select device_id, device_type from root.in.hyd.v2024, root.in.hyd.v2025
select device_id, device_type from root.in.hyd.v2024, root.in.hyd.v2025 ALIGN BY DEVICE;聚合函数
- COUNT函数 # 返回由SELECT语句选择的时间序列(一个或多个)非空值的值数
- FIRST_VALUE函数 # 返回所选时间序列的第一个点值
- LAST_VALUE函数 # 返回所选时间序列的最后一个点值
- MAX_TIME函数 # 返回所选时间序列(一个或多个)的最大时间戳
- MAX_VALUE函数 # 返回所选时间序列(一个或多个)的最大值
- AVG函数 # 返回指定时间段内所选时间序列的算术平均值
- MIN_TIME 函数 # 返回所选时间序列的最小时间戳
- MIN_VALUE 函数 # 返回所选时间序列(一个或多个)的最小值
- NOW 函数 # 返回当前时间戳
- SUM 函数 # 返回指定时间段内所选时间序列的总和
删除序列
按照条件删除:
-- 删除单个时间序列
delete from root.BHSFC.Q1.W003.speed
delete from root.BHSFC.Q1.W003 where time<=2022-01-14T00:00:00
-- 删除设备 device 上所有的 timeseries
DELETE TIMESERIES root.in.hyd.v2025.**;设置 TTL 的 SQL 语句为:
-- 表示在 root.BHSFCQ1.W003 设备中,最近一个小时的数据将会保存,旧数据会被删除。
set ttl to root.BHSFC.Q1.W003 3600000
-- 取消TTL
unset ttl to root.BHSFC.Q1.W003我们还可以查询目前已设置的 TTL ,SQL 语句为:
show all ttl