缘起,大约在 2014 年,经过过一次 HBase 崩溃(那个时候公司的服务器都在公司放着,停电引起),HBase 无法启动,经过检查,是 HBase 的 HFile 文件损坏。于是,开始研究 HBase 的 HFile 文件格式, 着手抢救 HBase 中的数据。那时候,从 zookeeper 中读取 hbase 表 meta 信息,从meta 分析hbase 的 region,从而从 HDFS 上读取对应 region 的数据备份,并尝试自己读取 hfile。经过这次,对 HFile 文件格式有了深入了解,后续又对 SequenceFile、ParquetFile、ORC等文件格式进行了一些了解,写了一些读写的例子,但后续的工作原因都并没有深入下去。
最近,因为看到新公司的系统,还在采用 JSON File 存储历史,但是又考虑存储大小,又对 JSON 进行一次 zip 格式压缩,着实麻烦。就有了想用 ParquetFile、ORCFile 采用 snappy 压缩格式来一次性解决。于是又翻了翻以前的代码,再系统性的学习下几种存储格式。
SequenceFile 文件
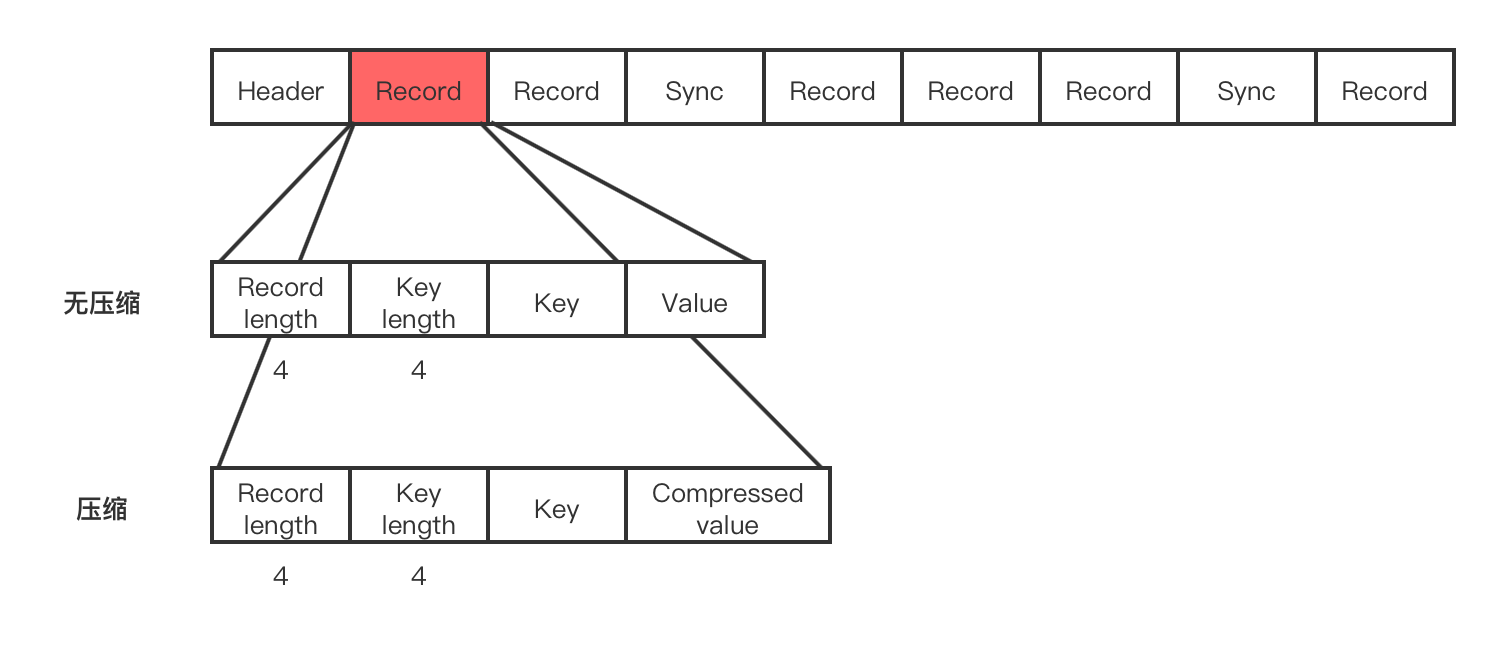
SequenceFile 是 基于 Hadoop Writable 的一种序列化文件格式。HDFS文件系统是适合存储大文件的,很小的文件如果很多的话对于 Namenode 的压力会非常大,因为每个文件都会有一条元数据信息存储在 Namenode上, 当小文件非常多也就意味着在 Namenode上存储的元数据信息就非常多。SequenceFile 将小文件合并起来,可以获得更高效率的存储和计算。SequenceFile 中的 key 和 value 可以是任意类型的 Writable 或者自定义 Writable 类型。
写 SequenceFile 文件
IntWritable key = new IntWritable();
Text value = new Text();
// 构造Writer参数属性
SequenceFile.Writer writer = null;
CompressionCodec Codec = new SnappyCodec();
SequenceFile.Writer.Option optPath = SequenceFile.Writer.file(path);
SequenceFile.Writer.Option optKey = SequenceFile.Writer.keyClass(key.getClass());
SequenceFile.Writer.Option optVal = SequenceFile.Writer.valueClass(value.getClass());
SequenceFile.Writer.Option optCom = SequenceFile.Writer.compression(SequenceFile.CompressionType.RECORD, Codec);
try {
writer = SequenceFile.createWriter(conf, optPath, optKey, optVal, optCom);
for (int i = 0; i < 100; i++) {
key.set(100 - i);
value.set("hello, SequenceFile, num: " + i);
writer.append(key, value);
}
} finally {
IOUtils.closeStream(writer);
}读 SequenceFile 文件
SequenceFile.Reader.Option option1 = SequenceFile.Reader.file(path);
// 这个 2048 参数表示读取的长度
// SequenceFile.Reader.Option option2 = SequenceFile.Reader.length(2048);
SequenceFile.Reader reader = null;
try {
reader = new SequenceFile.Reader(conf, option1, option2);
Writable key = (Writable) ReflectionUtils.newInstance(reader.getKeyClass(), conf);
Writable value = (Writable) ReflectionUtils.newInstance(reader.getValueClass(), conf);
long position = reader.getPosition();
while (reader.next(key, value)) {
String syncSeen = reader.syncSeen() ? "*" : "";// 是否返回了Sync Mark同步标记
System.out.println(String.format("[%s%s]\t%s\t%s\n", position, syncSeen, key, value));
position = reader.getPosition(); // beginning of next record
}
} finally {
IOUtils.closeStream(reader);
}理解:SequenceFile 文件,就像是从上倒下的顺序文件,采用 Key-Value 的2*N 的二维表格(不过这个表格内部可以采用复杂格式的 Writable 进行嵌套)。
ORC 文件
ORC(Optimized Row Columnar)是Hadoop生态系统中一种高效的列式存储文件格式,其主要特性包括高效压缩、快速读取、以及能够存储结构化数据。ORC 文件格式可能是 Hadoop 最常见的格式。
具有以下优势:
- 高效压缩:ORC文件支持多种压缩算法,如Snappy、Zlib等,可以显著减少存储空间。
- 快速读取:列式存储使得ORC文件能够快速读取特定列的数据,而无需读取整个行。
- 结构化数据支持:ORC文件可以存储复杂的结构化数据,如嵌套结构、列表和映射等。
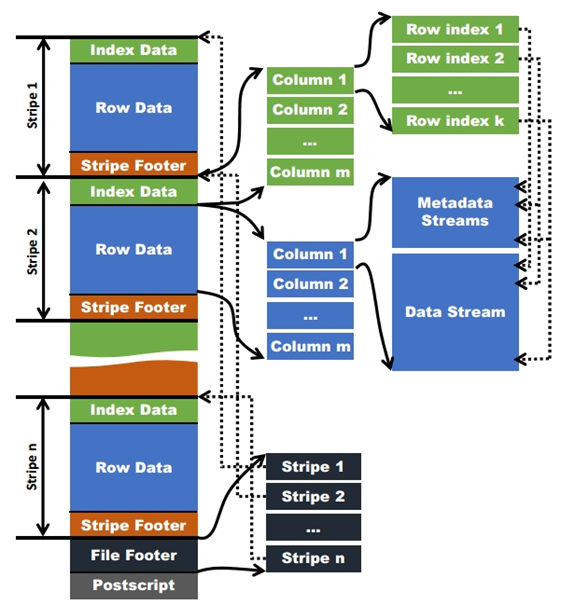
在ORC格式的hive表中,记录首先会被横向的切分为多个stripes,然后在每一个stripe内数据以列为单位进行存储,所有列的内容都保存在同一个文件中。每个stripe的默认大小为256MB,相对于RCFile每个4MB的stripe而言,更大的stripe使ORC的数据读取更加高效。
对于复杂数据类型,比如Map,ORC文件会将一个复杂数据类型字段解析成多个子字段。下表中列举了ORC文件中对于复杂数据类型的解析
| Data type | Chile columns |
|---|---|
| Array | 一个包含所有数组元素的子字段 |
| Map | 两个子字段,一个key字段,一个value字段 |
| Struct | 每一个属性对应一个子字段 |
| Union | 每一个属性对应一个子字段 |
写 ORC 文件
Configuration conf = new Configuration();
Path file = ......
TypeDescription schema = TypeDescription.fromString(
"struct<name:string,age:int>");
schema = TypeDescription.createStruct()
.addField("id", TypeDescription.createString())
.addField("content", TypeDescription.createString());
Writer writer = OrcFile.createWriter(
file, OrcFile.writerOptions(conf).setSchema(schema));
VectorizedRowBatch batch = schema.createRowBatch(128);
BytesColumnVector id = (BytesColumnVector) batch.cols[0];
BytesColumnVector content = (BytesColumnVector) batch.cols[1];
for (int i = 0; i < 10000; i++) {
// 先赋值,再加加,重点是让 batch.size 增加
int row = batch.size++;
id.setVal(row, String.valueOf(i).getBytes());
content.setVal(row, ("jason-" + i).getBytes());
if(row == batch.getMaxSize() - 1) {
writer.addRowBatch(batch);
batch.reset();
}
}
if(batch.size > 0) {
writer.addRowBatch(batch);
batch.reset();
}注意:VectorizedRowBatch 类型,他就是一个 batchSize 长的数组,目的就是批量写入。每次的赋值后,都要对 batch.size++ 处理,这样后续的赋值才能赋值到不断递增的 batch 中,否则总是赋值到内部数组为0的位置上(刚开始在这个地方误解了很久)。
读 ORC 文件
Configuration conf = new Configuration();
Path file = ......
Reader reader = OrcFile.createReader(file, OrcFile.readerOptions(conf));
// 获取 Schema
TypeDescription schema = reader.getSchema();
System.out.println("ORC 文件 Schema: " + schema);
// 创建 RecordReader
RecordReader recordReader = reader.rows();
// 创建 VectorizedRowBatch
VectorizedRowBatch batch = schema.createRowBatch();
BytesColumnVector id = (BytesColumnVector) batch.cols[0];
BytesColumnVector content = (BytesColumnVector) batch.cols[1];
while (recordReader.nextBatch(batch)) {
for (int row = 0; row < batch.size; row++) {
String idStr = new String(id.vector[row], id.start[row], id.length[row]);
String name = new String(content.vector[row], content.start[row], content.length[row]);
System.out.println("ID: " + idStr + ", Name: " + name);
}
}ParquetFile 文件
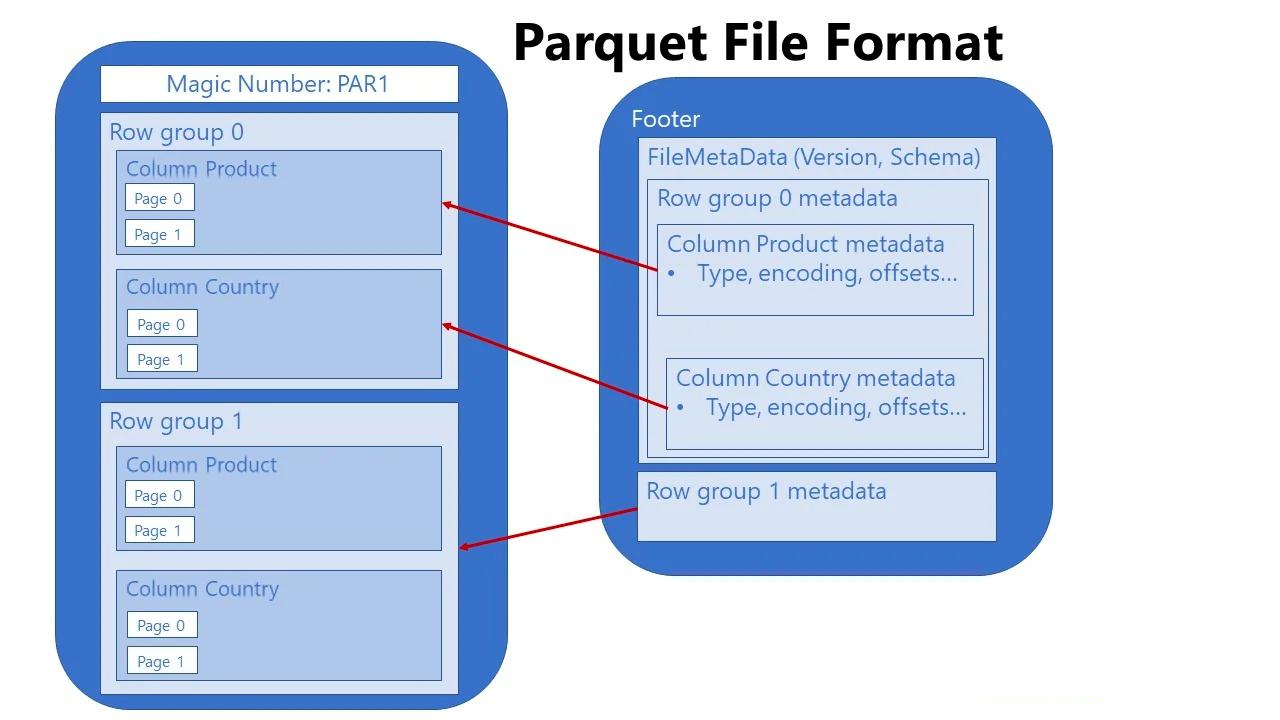
Parquet 是一种基于列的存储格式。Parquet 文件格式是自解析的,采用 avro 格式定义的文件 schema 以及其他元数据信息一起存储在文件的末尾。Parquet 和 ORC 采用列式存储形式,通常比 CSV 和 Avro 更具压缩性,基本构成了 Hadoop/Hive 上最通用的存储格式。Parquet 文件具有一下特性:
- 数据压缩:通过应用各种编码和压缩算法,Parquet 文件可减少内存消耗,减少存储数据的体积。
- 列式存储:快速数据读取操作在数据分析工作负载中至关重要,列式存储是快速读取的关键要求。
- 与语言无关:开发人员可以使用不同的编程语言来操作 Parquet 文件中的数据。
- 开源格式:这意味着您不会被特定供应商锁定
- 支持复杂数据类型
Parquet 文件存储格式如下:
写 ParquetFile 文件
采用 avro schema 定义:
// 定义 Avro Schema
String schemaJson = "{"
+ "\"type\": \"record\","
+ "\"name\": \"User\","
+ "\"fields\": ["
+ " {\"name\": \"id\", \"type\": \"string\"},"
+ " {\"name\": \"name\", \"type\": \"string\"}"
+ "]}";
Schema schema = new Schema.Parser().parse(schemaJson);
Path file = ......
// 创建 ParquetWriter
try (ParquetWriter<GenericRecord> writer = AvroParquetWriter.<GenericRecord>builder(file)
.withSchema(schema)
.withConf(new Configuration())
.withWriteMode(org.apache.parquet.hadoop.ParquetFileWriter.Mode.OVERWRITE)
.build()) {
// 创建数据
GenericRecord record = new GenericData.Record(schema);
record.put("id", 1);
record.put("name", "Alice");
writer.write(record);
record.put("id", 2);
record.put("name", "Bob");
writer.write(record);
}采用 JavaBean Reflect 定义:
Path dataFile = ......
Schema schema = ReflectData.AllowNull.get().getSchema(GuiJi.class);
try (ParquetWriter<GuiJi> writer = AvroParquetWriter.<GuiJi>builder(dataFile)
.withConf(conf)
.withSchema(schema)
.withDataModel(ReflectData.get())
.withCompressionCodec(CompressionCodecName.UNCOMPRESSED)
.withWriteMode(ParquetFileWriter.Mode.OVERWRITE)
.build()) {
for (GuiJi user : users) {
writer.write(user);
}
}读 ParquetFile 文件
Configuration conf = new Configuration();
Path dataFile = ...
// final ParquetReader<GenericRecord> reader = AvroParquetReader.genericRecordReader(dataFile);
try(ParquetReader<GenericRecord> reader = AvroParquetReader.<GenericRecord>builder(dataFile)
.withDataModel(GenericData.get()) // 这里可以指定 schema
.withConf(conf)
.build();) {
GenericRecord g = null;
int count = 0;
while ((g = reader.read()) != null) {
count++;
System.out.println(count + " " + g);
}
}TsFile
tsfile 是 IOTDB 的存储文件格式,全称是Time Series File。采用列式存储,支持时序数据的压缩和索引。
TsFile数据模型
TsFile有设备、物理量(测点)、时间和值这四个状态,图中是两个TsFile的典型模型。

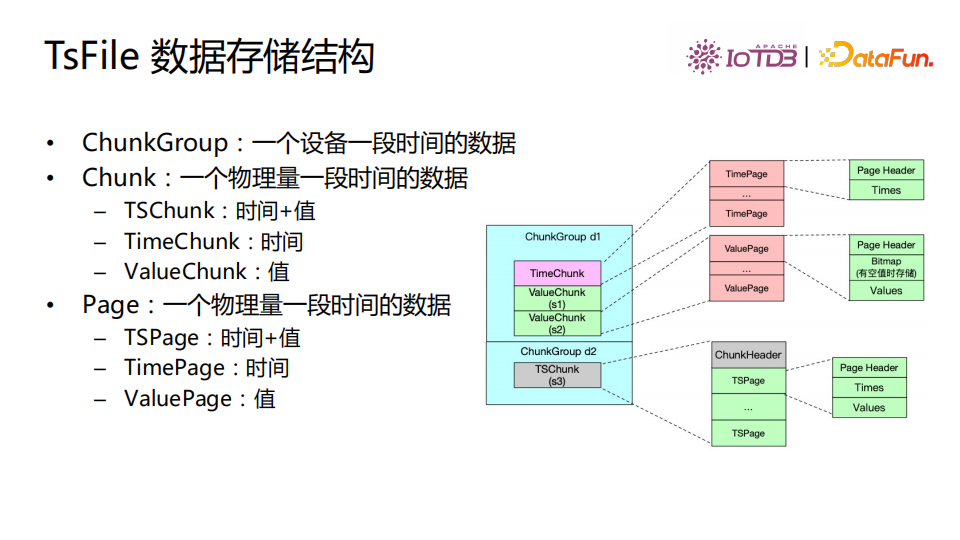
数据存储结构
TsFile数据存储结构如图。ChunkGroups存储一个设备一段时间写入的数据。Chunk是一个物理量一段时间的数据,分为三种Chunk:(1)TSChunk,时间+值;(2)TimeChunk,时间;(3)ValueChunk,值。在Chunk基础上我们又把数据划分成Page,Page是一个物理量一段时间的数据,有三种Page:(1)TSPage,时间+值;(2)TimePage,时间;(3)ValuePage,值。通过这种方式,TsFile采用分级的数据存储结构进行管理。
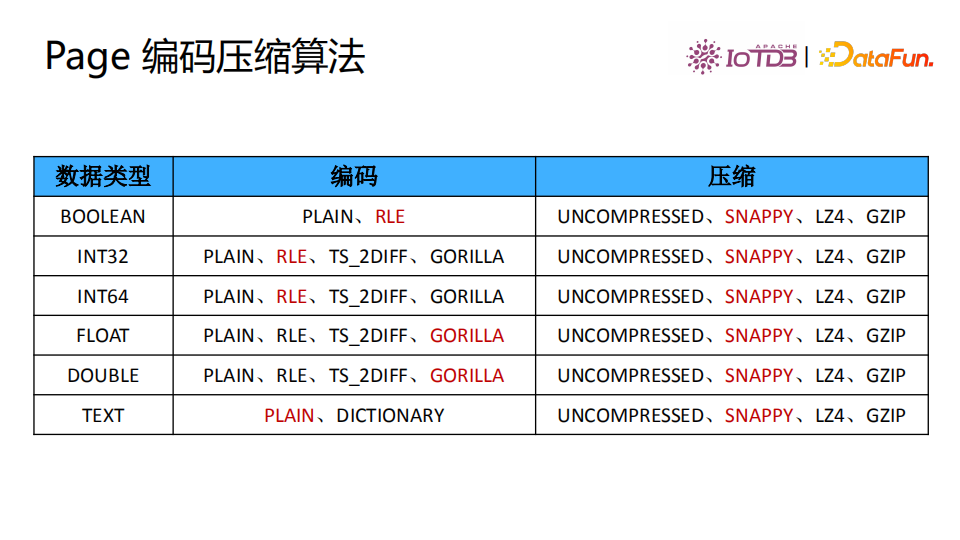
Page 编码压缩算法
Page是数据最小粒度,可以对Page进行编码和压缩。图中展示了几种编码和压缩算法,红色的是数据类型的默认压缩编码与使用的算法。
写 TsFile 文件
采用 TSRecord 单条写入:
TsFileWriter writer = new TsFileWriter(new TsFileIOWriter(fsFile));
long timestamp = System.currentTimeMillis();
List<MeasurementSchema> schemas = Lists.newArrayList(
new MeasurementSchema("sensor_data", TSDataType.STRING),
new MeasurementSchema("temperature", TSDataType.FLOAT)
);
// 注册设备
writer.registerTimeseries(new Path("aaa"), schemas);
for (int i = 0; i < 1000; i++) {
// 时间一定是递增的,否则会抛出错误
TSRecord record = new TSRecord(timestamp++, "aaa");
record.addTuple(new StringDataPoint("sensor_data", new Binary("fix-" + i, StandardCharsets.UTF_8)));
record.addTuple(new FloatDataPoint("temperature", (float) (Math.random() * 100)));
writer.write(record);
}采用 Tablet 批量写入:
TsFileWriter writer = new TsFileWriter(new TsFileIOWriter(fsFile));
List<MeasurementSchema> schemas = Lists.newArrayList(
new MeasurementSchema("sensor_data", TSDataType.STRING),
new MeasurementSchema("temperature", TSDataType.FLOAT)
);
// 注册设备
writer.registerTimeseries(new Path("aaa"), schemas);
Tablet tablet = new Tablet("aaa", schemas);
long timestamp = System.currentTimeMillis();
for (int i = 0; i < 100; i++) {
int row = tablet.rowSize++;
tablet.addTimestamp(row, timestamp++);
// temperature 值
tablet.addValue("sensor_data", row, "abcdefg");
tablet.addValue("temperature", row, (float) (Math.random() * 100));
// 当时间戳数目达到阈值(tablet.getMaxRowNumber())时,将当前的tablet写入TsFile,并清空tablet以继续重复该流程来将剩余时间序列信息写入tsfile
if (tablet.rowSize == tablet.getMaxRowNumber()) {
writer.write(tablet);
tablet.reset();
}
}
// 如果最后还有没有写入TsFile的内容,将其写入
if (tablet.rowSize != 0) {
writer.write(tablet);
tablet.reset();
}读取 TsFile 文件
File fsFile = new File("data/guiji.tsfile");
// 创建 TsFileReader
TsFileReader tsFileReader = new TsFileReader(new TsFileSequenceReader(fsFile.getAbsolutePath()));
// 定义查询路径
List<Path> paths = new ArrayList<>();
paths.add(new Path("aaa.sensor_data", true));
paths.add(new Path("aaa.temperature", true));
// 创建查询表达式
QueryExpression queryExpression = QueryExpression.create(paths, null);
// 执行查询
QueryDataSet dataSet = tsFileReader.query(queryExpression);
// 读取数据
while (dataSet.hasNext()) {
RowRecord record = dataSet.next();
List<Field> fields = record.getFields();
final String line = fields.stream().map(f -> f.getStringValue()).collect(Collectors.joining("/"));
System.out.println("Timestamp: " + record.getTimestamp() + ", Value: " + line);
}
// 关闭读取器
tsFileReader.close();HFile
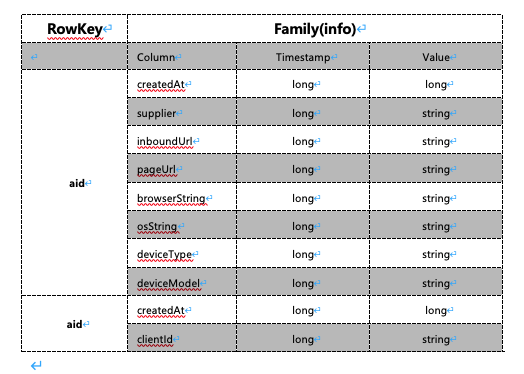
HFile是HBase存储数据的文件组织形式。HFile会被切分为多个大小相等的block,每一个block大小可以在创建表列簇的时候通过blockSize参数指定,默认是64K,较大的blockSize有利于scan,较小的有利于随即查询(get)。
CacheConfig cacheConfig = new CacheConfig(configuration);
HFile.Reader hreader = HFile.createReader(fs, new Path("/path/data/part-m-00000"),
cacheConfig, configuration);
// loadFileInfo
hreader.loadFileInfo();
HFileScanner hscanner = hreader.getScanner(false, false);
// seek to the start position of the hfile.
hscanner.seekTo();
// print values.
int index = 1;
while (hscanner.next()) {
System.out.println("index: " + index++);
System.out.println("key: " + hscanner.getKeyString());
System.out.println("value: " + hscanner.getValueString());
}HFile 存储结构如下: