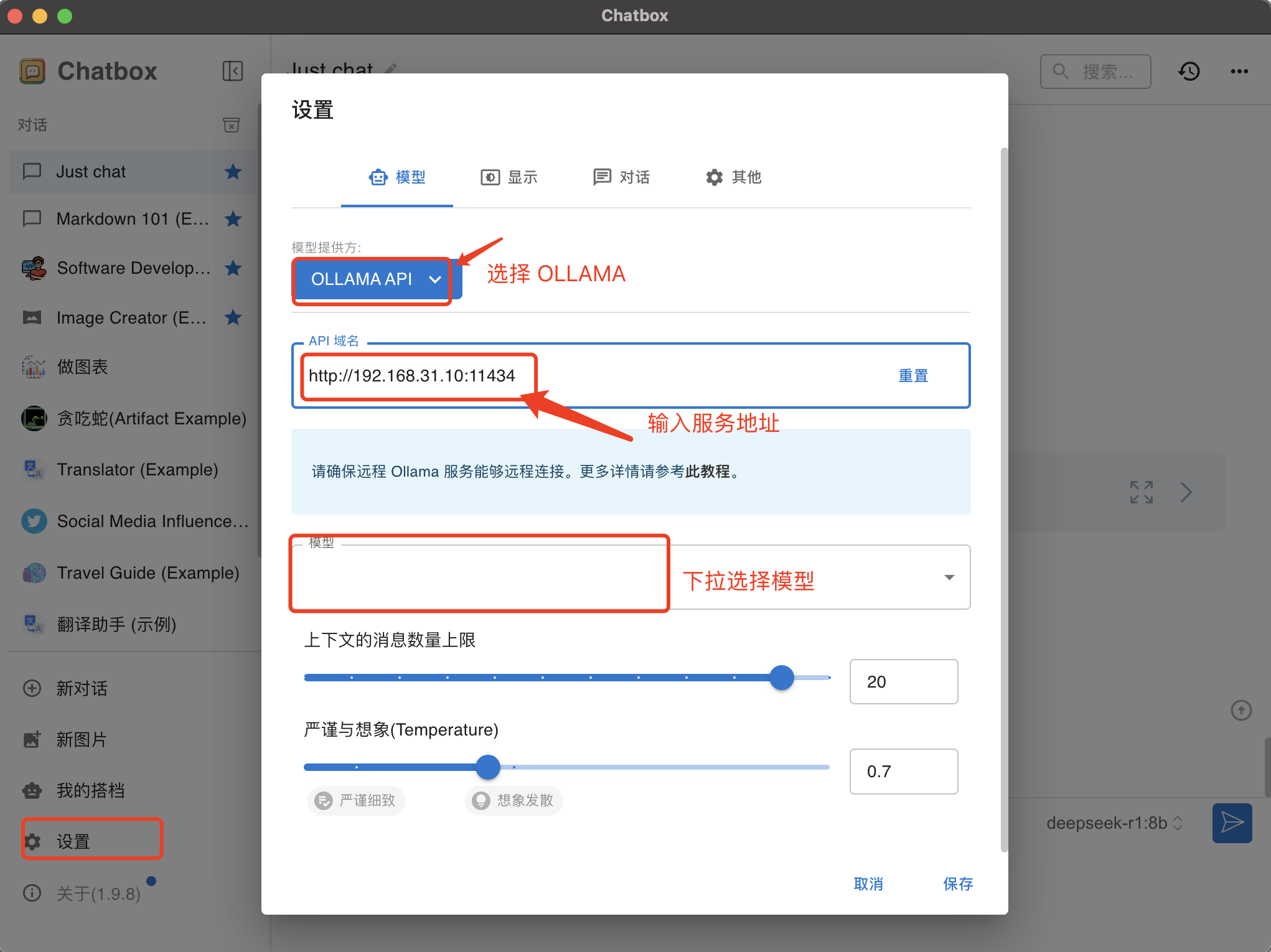
DeepSeek R1 安装指导和简单使用
本教程安装的服务器环境如下:
- Debian 12.6(Linux)
- 32GB内存, 20核心 E5-2697V2, SSD硬盘(无显卡)
- 梯子
DeepSeek-R1 安装
shell
curl -fsSL https://ollama.com/install.sh | sh
# 国内可访问
curl -fsSL https://aliendao.cn/ollama/install.sh | sh安装成功后,需要在 /etc/systemd/system/ollama.service 文件中添加 OLLAMA_HOST 用于将服务绑定到 IP 对应的网卡上(否则外部无法调用):
shell
Environment="OLLAMA_HOST=ip:11434"
# 或
vim /etc/profile
export OLLAMA_HOST=ip:11434
source /etc/profile注意:这里的 ip 不能写 0.0.0.0,需要填写内网 IP,否则外部无法访问。
修改后,重启服务:
shell
systemctl daemon-reload
systemctl restart ollama其他相关配置
可在 /etc/profile 配置环境变量:
shell
# ollama 使用 gpu 架构,cuda
OLLAMA_GPU_LAYER=cuda
# ollama 使用显卡device,可通过 nvidia-smi 查看显卡编号,一块一般为0,多块 0..n
CUDA_VISIBLE_DEVICES=0,1
# ollama 绑定的服务 address,内网IP,否则只能本机
OLLAMA_HOST=ip:11434
# ollama 下载的模型文件存储地址
OLLAMA_MODELS=/path/ollama/models也可再 /etc/systemd/system/ollama.service 添加环境变量。
ini
# vim /etc/systemd/system/ollama.service
Environment="OLLAMA_HOST=ip:11434"无论哪种方式配置,都要重启 ollama,或者 source /etc/profile 再重启 ollama。
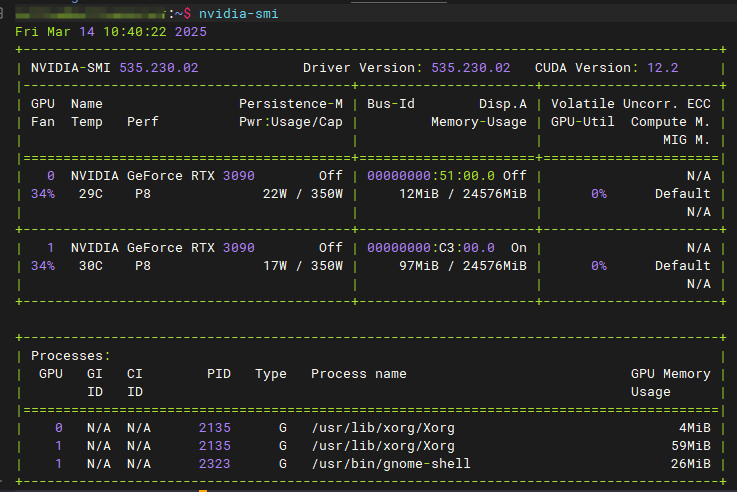
模型并行参数
- OLLAMA_KEEP_ALIVE=24h #设置模型加载到内存中保持24个小时(默认情况下,模型在卸载之前会在内存中保留 5 分钟)
- OLLAMA_NUM_PARALLEL=10 # 设置 10 个用户并发请求
- OLLAMA_MAX_LOADED_MODELS=2 # 设置同时加载多个模型, 自行考虑 GPU 情况
模型选择
官方模型地址:https://ollama.com/library/deepseek-r1:8b
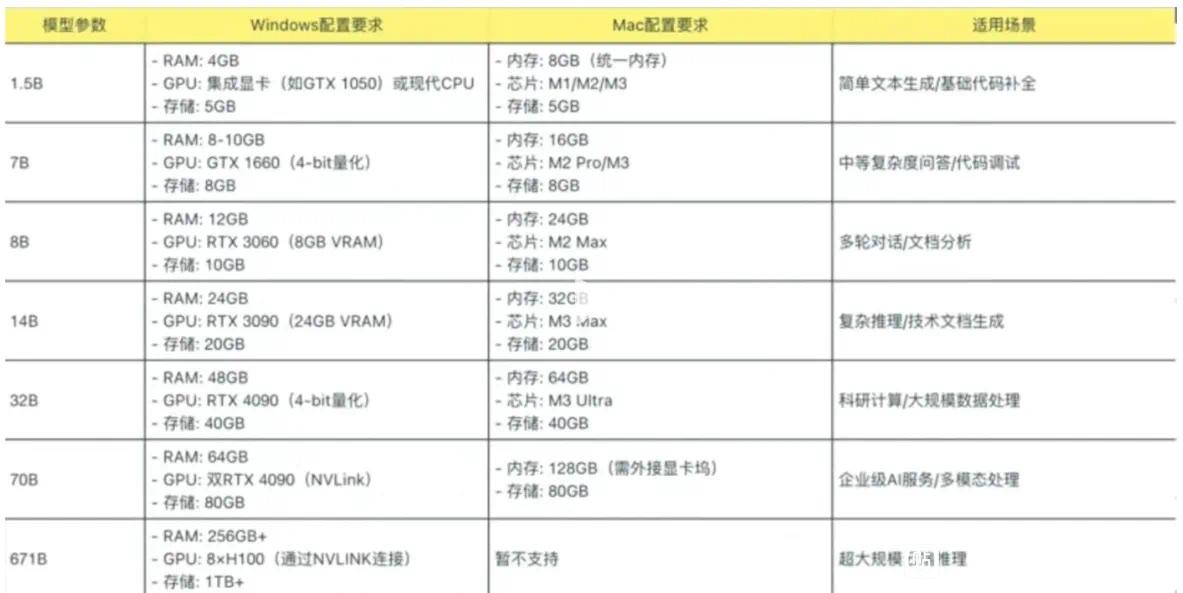
DeepSeek-R1 安装所需内存介绍:
官方推荐介绍:
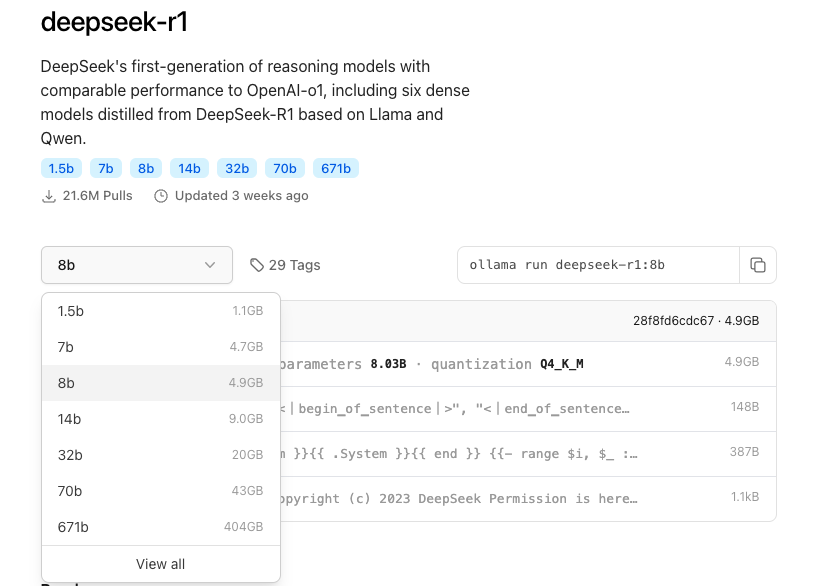
shell
ollama run deepseek-r1:1.5bDeepSeek-R1-Distill-Qwen-7B
shell
ollama run deepseek-r1:7bDeepSeek-R1-Distill-Llama-8B
shell
ollama run deepseek-r1:8bDeepSeek-R1-Distill-Qwen-14B
shell
ollama run deepseek-r1:14bDeepSeek-R1-Distill-Qwen-32B
shell
ollama run deepseek-r1:32bDeepSeek-R1-Distill-Llama-70B
shell
ollama run deepseek-r1:70b安装过程:

下载的模型,默认保存在:/usr/share/ollama/.ollama,copy 该地址可迁移 ollama。
简单使用
通过 ollama run 即可运行指定的模型,并再运行的控制台进行交互。
也可安装 Chatbox 应用,进行图形化交互。